
Pourquoi je me suis lancé dans la création de Sections, un middleware pour accélerer les APIs
Publié 10 Jun 2025
La génèse de Sections API

Au cours des dernières années j'ai eu la chance d'accompagner des projets de sites web aux contenus personnalisés avec un haut niveau de trafic.
Lorsque le nombre de visites dépasse un certain seuil, les contraintes imposés ne sont plus les memes et le code/l'infra qui tourne sans sourciller lorsque vous etes le seul visiteur de votre site, n'arrive plus a suivre.
Il y a plusieurs niveaux de traffic à distinguer et nous pouvons les grouper en quatres categories:
| Niveau de traffic | Volume de visites quotidiennes |
| Faible | < 500 |
| Moyen | 500 à 5 000 |
| Elevé | 5 000 à 50 000 |
| Tres elevé | > 50 000 |
Les optimisations de performances sont nécessaires à partir du moment ou le seuil de traffic elevé est franchi.
Néanmoins, lorsqu'il s'agit d'optimiser les performances, le niveau de traffic n'est pas tout et le type de contenu que le site doit produire impacte grandement les besoins en resources.
A titre d'exemple, un site dit statique, comme un site vitrine, n'aura pas les memes besoins qu'un site eCommerce avec un moteur de recherche et/ou des recommendations personnalisés basées sur un historique d'achat et/ou des produits deja visités.
Afin de rester simple, on pourrait catégoriser les types de sites ainsi:
- Statique/Brochure
- Dynamique (blog, publications)
- Personnalisé (e-commerce, marketplace, annuaire avec moteur de recherche, SaaS etc..)
Optimisation des performances serveur
Une fois que le site est catégorisé, nous pouvons alors passer a l'action. Je vais déliberement ommetre les sujets relatifs aux assets et optimisations coté navigateurs (CDN, minification, compression, ré-écriture des scripts etc...) et me restreindre aux optimisations serveur.
La raison de cette approche est simple, la réponse du serveur est incompressible et c'est cette réponse qui va donner le "top départ" au navigateur pour demarrer le rendu de la page et le chargement de resources pour finaliser l'affichage de cette dernière.
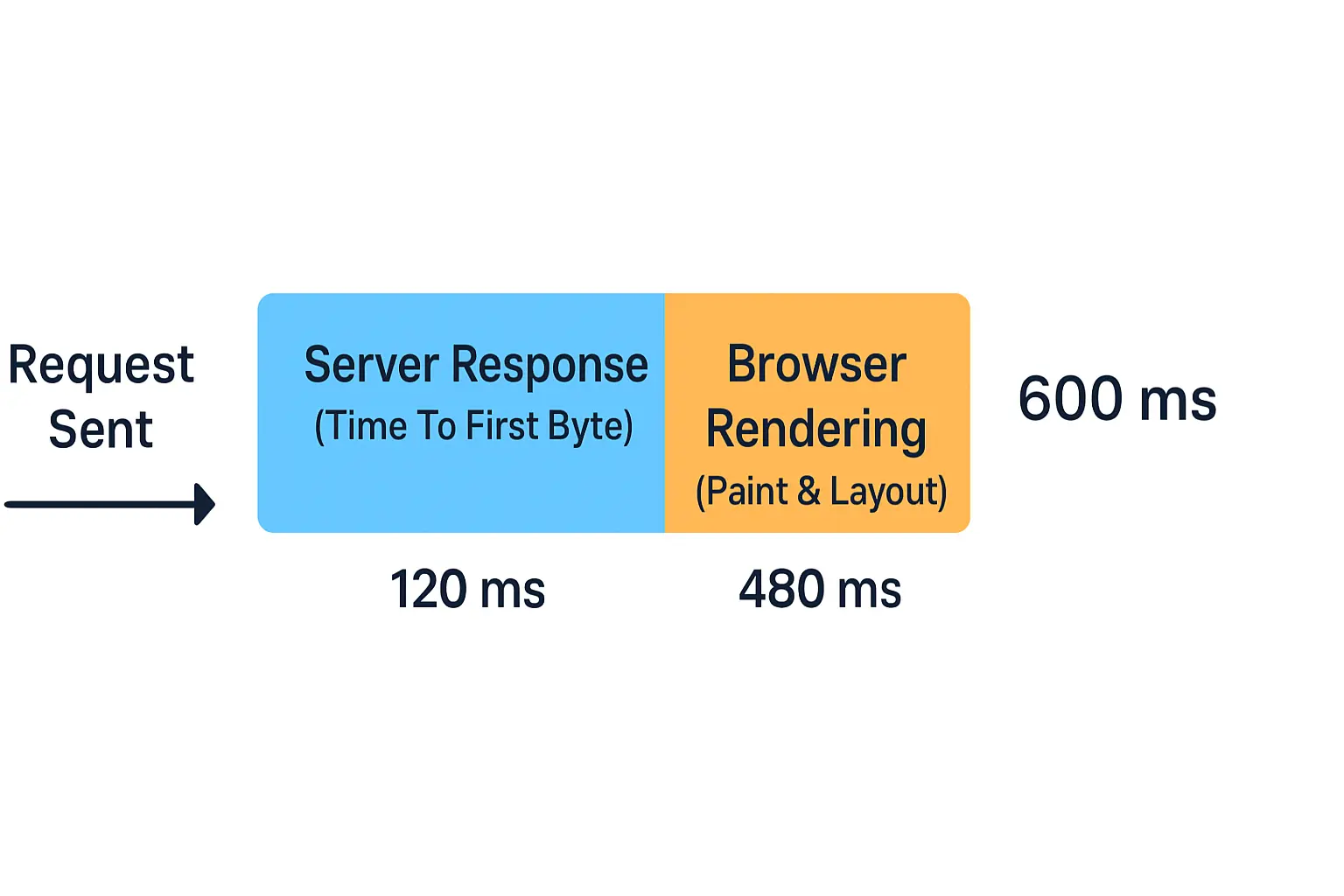
Site statique
En générale ce genre de site ne reçoit pas beaucoup de traffic, il est donc improbable de faire face à des besoins d'optimisations. Malgrès tout, j'ai deja pu voir des clients scinder leur site entre pages statiques et pages dynamiques, cela leur a permit de generer les pages statiques en amont, de les stocker sur un simple serveur web et de les servir en tant que tel. L'avantage de cette approche ? Plus de requetes en BDD à l'affichage, un simple televersement de la page HTML du serveur au navigateur.
L'inconvenient ? l'ajout de nouveau contenu peut déclencher une regeneration de plusieurs pages, l'evolutilié est limité et la navigation entre pages statiques et dynamique nécessite une configuration minutieuse.
Site dynamique
Avec un site dynamique, la génération anticipé n'est pas toujours une bonne idée. La quantité de contenu peut rapidement exploser (hello IA générative) et saturer le système de fichier. S'il faut en plus de ça prévoir des contenu traduits, des visiteurs du monde entier etc... il devient plus efficace d'eviter trop de redondance sur les contenus similaires (head, structure html etc..) et plutot mettre en cache les contenus qui sont dynamiques. Des outils assez populaire comme Redis sont utilisés à cette fin et fonctionne tres bien. Cela vient légerement complexifier l'infrastructure et il faut également anticiper les règles relatives à la gestion de ce cache (mise à jour de contenu, suppression de contenu etc...)
Dans l'ensemble cela fonctionne relativement bien une fois en place.
En contre partie, la maintenabilité en prend un coup et il faut intégrer les contraintes de cache dans les phases de design des évolutions applicatives.
Site personnalisé
Avec du contenu personnalisé, c'est une autre paire de manche. En effet, il devient pratiquement impossible d'anticiper toutes les combinaisons de contenu possible, le serveur va devoir génerer du contenu a la volé. Dans ces cas de figure, la mise en cache reste possible mais pas de manière intégrale. Il faut finement identifier les contenus qui peuvent "rentrer dans le cache" de ceux qui doivent etre generé à la volé. Les règles d'ajout au cache peuvent devenir complexe avec une logique d'invalidation et de reconstruction basé sur une dimension temps ou d'autres événements spécifique à la logique de l'application. Cette complexité a un impact directe sur les phase de conception et de test des applications et les effets de bords sont fréquents. D'un point de vue technique, des disciplines comme le Edge Side Includes (ESI) permet d'obtenir une granularité fine sur les contenu exclus du cache, mais il faut etre habile et savoir jongler avec des contraintes non lié a l'experience utilisateur mais qui restent critiquent pour le business comme le referencement.
Le problème récurrent
Ce genre de projets d'optimisation serveur sont souvent accompagnés:
- d'une ré-écriture partielle du code applicatif pour s'adapter a l'infrastructure a mettre en place.
- d'une configuration fine des stack serveur
- de compromis a faire entre performance, cout et experience utilisateur
- de monté en compétence coté client pour mieux comprendre la complexité des nouveaux comportements de l'applicatif
Ce n'est pas pour rien qu'on parle de boite noire: Les efforts a deployer sont difficilement connu a l'avance et les gains a en tirer ne sont pas évident a prévoir.
C'est précisément pour cela qu'un jour une idée m'est venu de faire autrement. Après tout, l'objectif est simple, réduire le temps nécessaire au serveur d'envoyer le contenu au navigateur...
L'approche empirique a toujours été de traiter une requete séquentiellement, historiquement cela se comprend, les processeurs monocoeur ont pousser les languages a operer de manière séquentiel.
Avec l'arrivé de processeurs multicoeurs, il est devenu possible de génerer différent contenu en meme temps, on parle ici de parrallelisme. Malheureusement cette possibilité n'est toujours pas accessible (j'entends ici une accessibilité lié au cout de mise en place mais également d'execution) avec des technologies "standards" (i.e PHP, Java, Javascript, Python etc...), en effet ces technologies vont soit faire appel a des threads (lourd a executer) soit faire du pseudo-parallelism (aussi appelé time slicing)
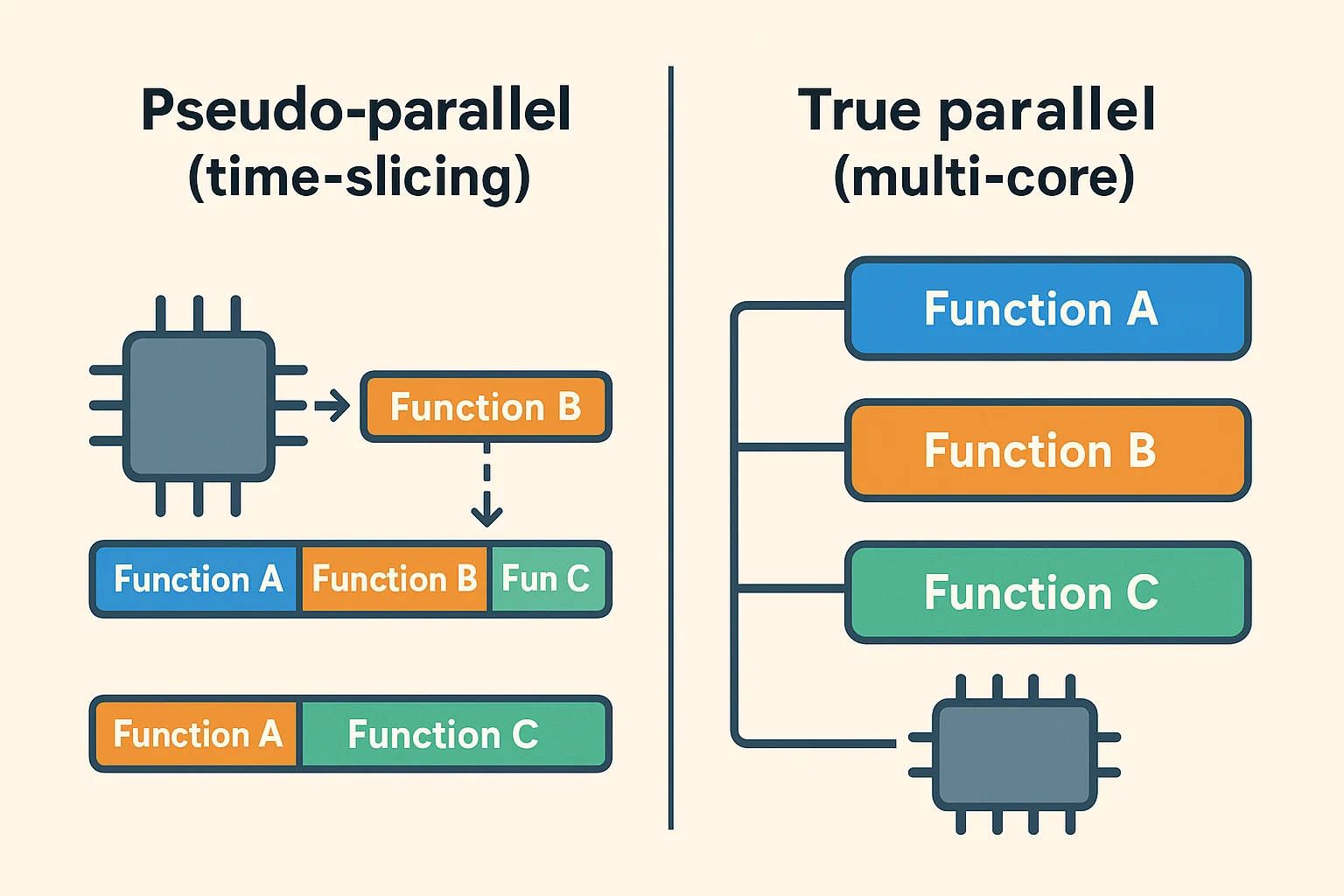
Une approche revisité
Sections exploite l'idée qu'une page est un agrégat de contenus qui peuvent (et doivent) etre génères en parallèle.
J'ai donc commencer a construire une application capable de récupérer les différentes "sections" d'une page en meme temps, de regrouper le tout en une seule réponse et de retourner la page au navigateur pour finaliser son affichage.
Les avantages sont multiples:
- Un temps de réponse bas
- Un temps de réponse stable et décorrelé de la "taille" de la page a servir
- Les besoins en cache réduit voir absent
- Un impact frontend nul
Le principe est simple, l'implementation, qui se devait d'etre suffisamment générique pour gérer différentes sources de contenu, l'est moins.
La première version de cette application a vu le jour en 2019, depuis j'ai pu deployer Sections sur plusieurs projets. A date la charge maximale que nous avons constaté sur un projet est de ±100 000 visites par jour.
Depuis, avec mon équipe, nous avons construit une version SaaS de cet outil, et complémenter l'API avec un CMS open source.
Il s'agit d'un projet en cours de développement, vous pouvez obtenir plus d'informations sur les liens suivants:
| Site | URL |
| Site web du CMS | https://sections.geeks.solutions |
| Repo github du CMS | https://github.com/Geeks-Solutions/sections-cms |
| Site web de l'API (contenu non mis à jour) | https://sections-api.geeks.solutions/ |

Julien Fayad
Je suis ingénieur logiciel passionné par l'utilisation des technologies innovantes pour solutionner les problèmes du monde actuel. J'entreprends depuis plus de 15 ans dans le domaine de la tech. J'ai evoluer dans les marchés du moyen orient, d'Europe et des USA. Apres 10 ans passé a Beyrouth, je vis maintenant à Paris et suis tres heureux de contribuer a l'écosystème des startups tech parisienne en tant que mentor à l'incubateur Telecom Paris